库存周转天数 vs 周转率,仓库到底看哪个?
很多企业的库存管理,都有一个非常典型的内耗场景:
财务说:库存周转率提升了,今年不错
仓库说:库里一堆老料根本动不了
采购说:我已经在压库存了
销售说:怎么还缺货?
最后结论是——谁都没错,但库存还是乱的。
问题不在执行,而在一个更底层的问题:库存到底该看“周转率”,还是看“周转天数”?

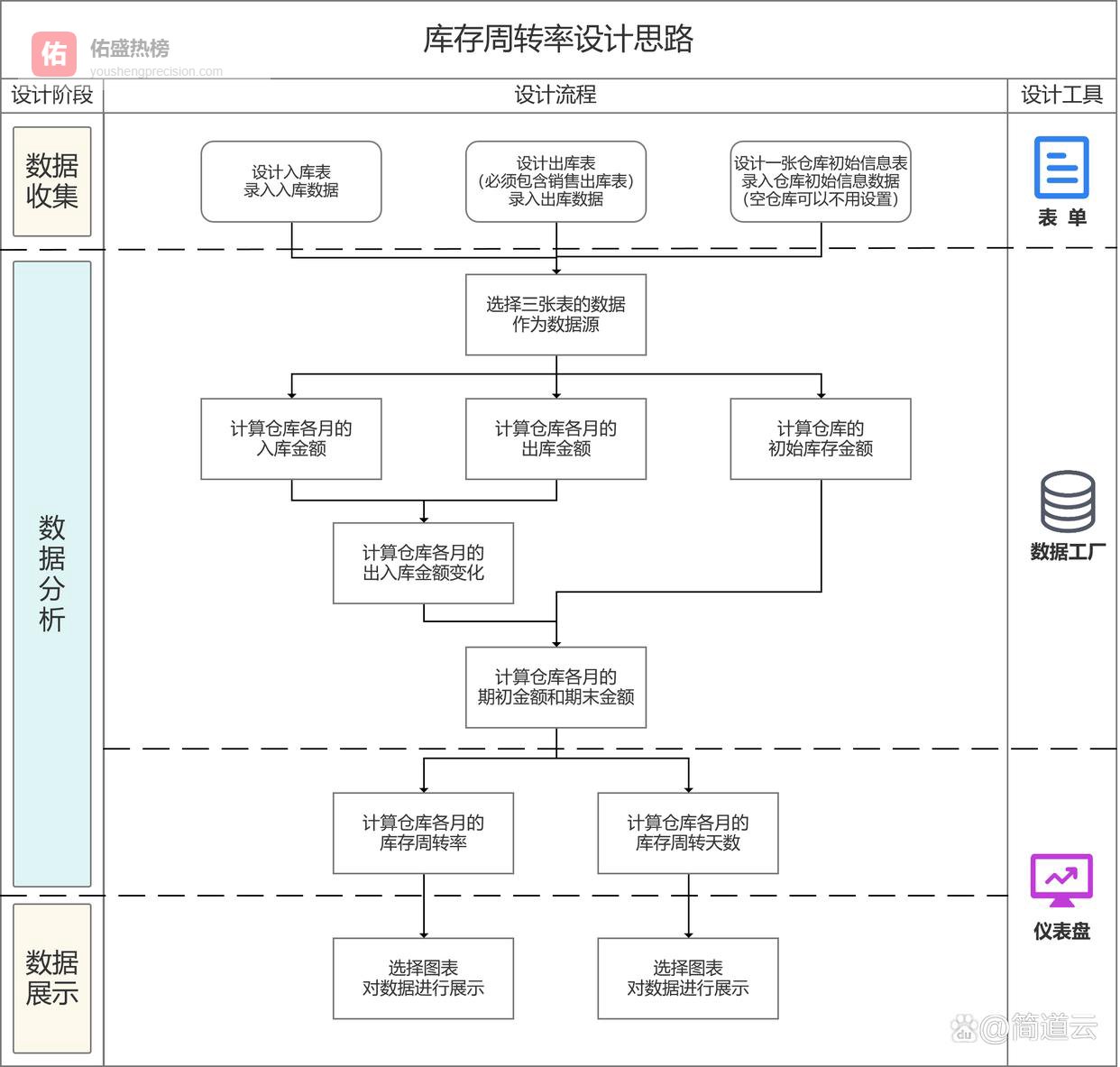 一、库存周转率vs周转天数:根本不是一类东西
一、库存周转率vs周转天数:根本不是一类东西很多人会纠结选哪个,但其实一开始就理解错了,它们不是竞争关系,是两个不同视角。
1. 库存周转率:一年这批货转了几次周转率 = 你的库存一年“流动了多少轮”
它本质是一个效率指标,老板喜欢它,因为它能回答:
钱有没有动起来
公司运营效率高不高
行业里处于什么水平
但它有个天然问题:它是平均数,非常容易掩盖结构问题。
2. 库存周转天数:货平均在仓库待多久周转天数 = 一件货从入库到出库平均要多少天
它解决的是:
库存是不是压住了
哪些物料在拖库存
哪些是风险库存
仓库更关注这个,因为它每天都在发生。
二、真正的分歧:不是指标问题,是视角错位一个很现实的情况:财务看整体效率,仓库看局部风险,于是就出现周转率很好,但仓库爆仓。
我们拆一下本质原因。
1. 周转率的问题:被爆款拉高举个真实结构:2个SKU卖爆,8个SKU滞销,结果周转率很好看,但现实是:
仓库被C类物料占满
新货进不来
老货清不掉
也就是说周转率解决不了结构问题。
2. 周转天数的问题:容易误判周转天数的问题是:
原材料本来就有备货周期
不同物料差异很大
行业标准不同
如果只盯天数,会出现过度压库存 → 影响生产稳定。
所以说,周转率是结果指标,周转天数是过程指标,一个看结果,一个看问题在哪。
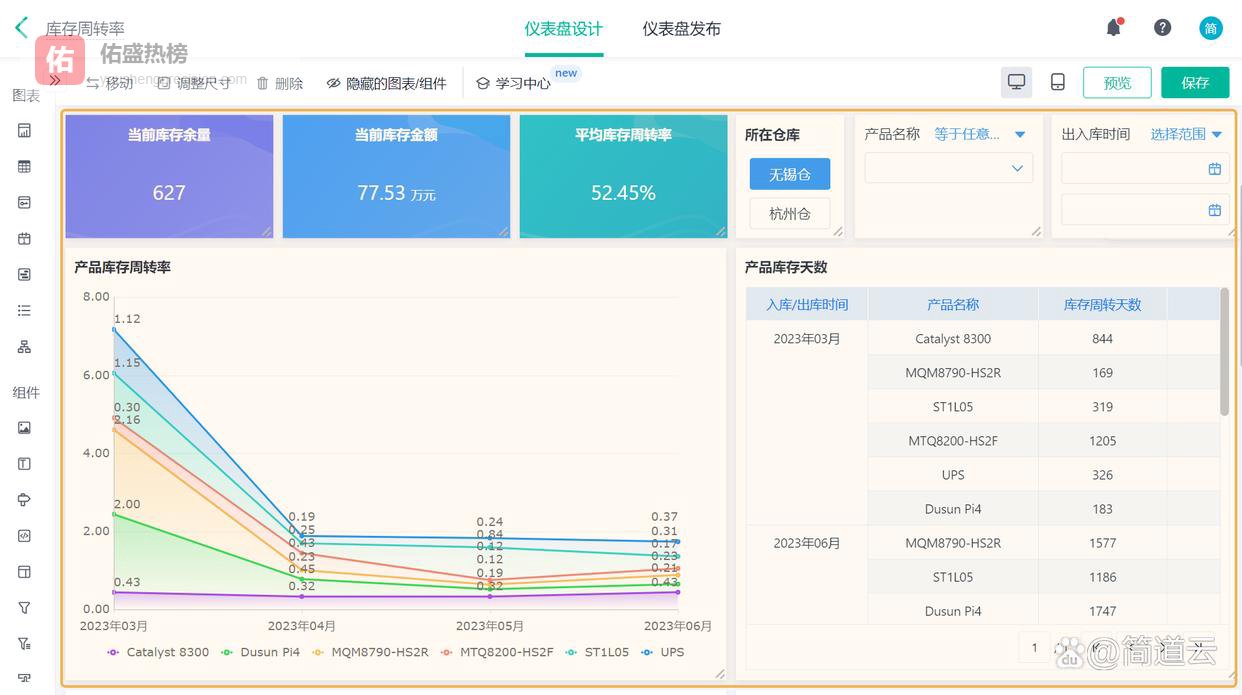 三、为什么很多公司两个指标都有,但库存还是乱?
三、为什么很多公司两个指标都有,但库存还是乱?这个才是核心,很多企业其实已经在做指标管理了,但依然失效,原因通常有三个。
1. 只看总数,不看结构典型情况——总库存周转率:6(很好看),但拆开SKU:
A类:15次
B类:5次
C类:0.6次
真正的问题全部在C类,但系统只告诉你一个平均值。
2. 数据分散,没有统一口径这个是最致命的问题:
财务一套数据
仓库一套Excel
采购一套逻辑
结果就是三个部门,三个库存版本。
3. 指标是算出来的,不是管出来的很多公司问题在这里:月底算一次周转率,月底才发现库存不健康,这时候已经晚了。
四、正确解法:不是选指标,而是建一套库存体系真正成熟的库存管理,不是看一个指标,而是三层结构。
第一层:老板看方向总库存周转率
库存金额
看趋势,不看细节。
第二层:供应链看结构SKU周转天数
ABC分类
库存结构健康度
这一层决定库存是否合理。
第三层:仓库看风险库龄(30/60/90天)
呆滞库存占比
超期预警
这一层决定怎么处理。
重点一句话:库存不是一个指标,而是一套分层系统。
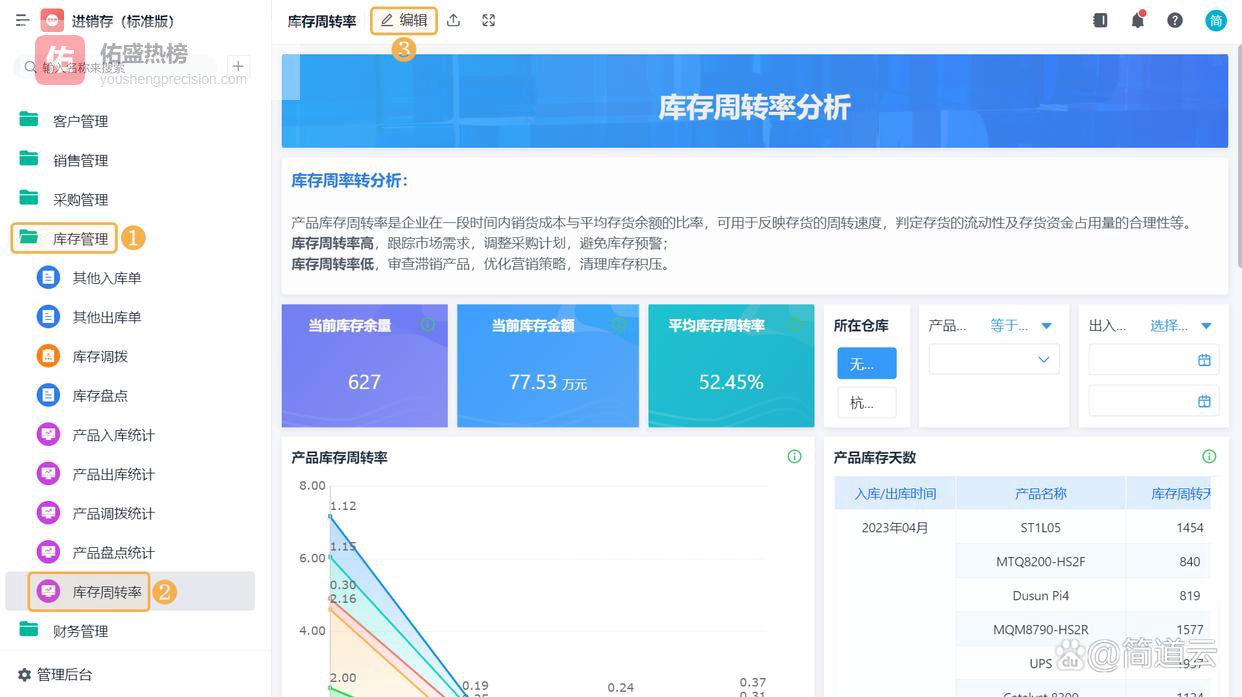 五、这套体系为什么90%公司做不起来?
五、这套体系为什么90%公司做不起来?原因其实很现实:
Excel做不动实时数据
ERP数据颗粒度不够
各部门口径不统一
库龄和周转率要人工算
结果就是指标体系设计得很好,但跑不起来。
关键不是算指标,而是让系统自动跑,现在很多企业开始做一件事:用低代码工具,把库存管理从“人工计算”变成“自动系统”。
比如用简道云这类平台做库存体系时,核心不是做系统,而是做三件事:
1. 把库存数据打通(关键前提)把三块数据统一:
采购入库
销售出库
当前库存
统一之后,系统才能自动计算周转率、周转天数、库存结构,否则就是各算各的。
2. 自动算周转率 + 周转天数(不用人工)系统会基于实时数据自动生成:
SKU级周转率
SKU级周转天数
分类汇总数据
重点是不再依赖月底Excel人工统计。
3. 自动做ABC分类 + 库存结构分析比如:
按销量/金额自动划分A/B/C类
自动识别滞销SKU
自动标记库存异常
这一步很关键,因为解决的是“平均值掩盖结构问题”。
4. 自动预警库存风险(真正拉开差距的地方)比如设置规则:
30天未动 → 提醒
60天 → 预警
90天 → 强制处理
系统会自动推送,而不是靠人去盯。
这一整套下来,本质发生了一个变化:从人盯库存变成系统盯风险。
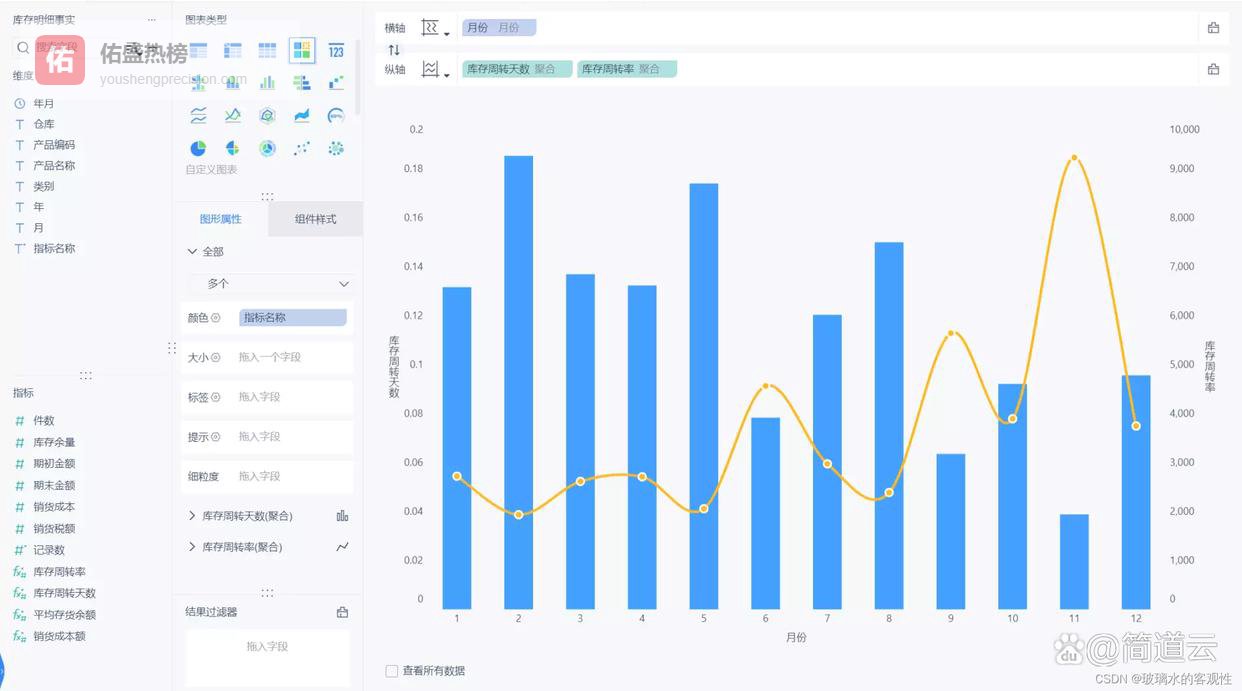
很多人以为库存管理是在管:
周转率
周转天数
但真正核心是:库存结构是否健康
爆款是否稳定供货
长尾是否在被持续消化
是否存在隐性积压
指标只是结果,不是原因。
最后总结一句话库存周转率和周转天数,不是二选一的问题,而是分工问题。
周转率:看效率(老板视角)
周转天数:看风险(执行视角)
真正成熟的企业,不是选一个指标,而是用一套系统,把两个指标同时跑起来,并且自动联动库存结构。
能不能管好库存,不取决于你会不会算指标,而取决于你有没有一套能自动跑起来的系统。





