火山引擎AI平台:把万亿参数模型训练成“日常”
01模型训练到底难在哪?
1.1 ▍ 技术侧:需求千差万别自动驾驶、蛋白质结构预测、推荐广告、NLP…… 不同场景对算力、数据量、网络带宽的胃口各不相同。想让集群“吃得饱”又“不浪费”,底层硬件得硬核,调度系统得更聪明,才能把利用率死死摁在高位。
1.2 ▍ 管理侧:公平与复现的双重难题架构差异:同一算法,换套基础设施,效果可能“玄学”浮动。
复现难:不同团队、不同机器、不同版本,实验结果怎么横向对比?
一句话: 别让“基础设施”成为算法优劣的隐藏变量。
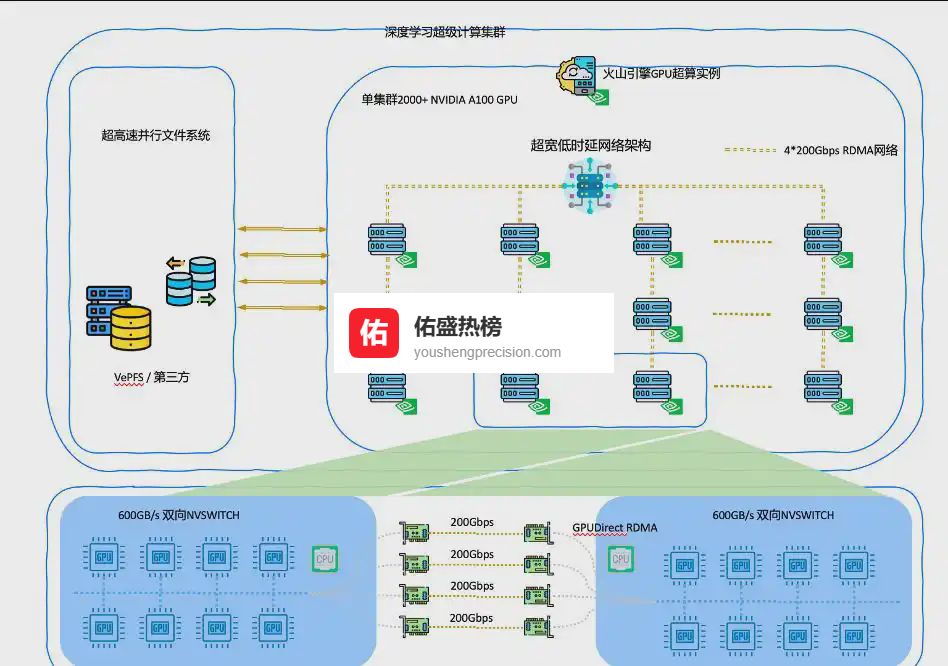
02平台架构:两把利刃,直击规模痛点
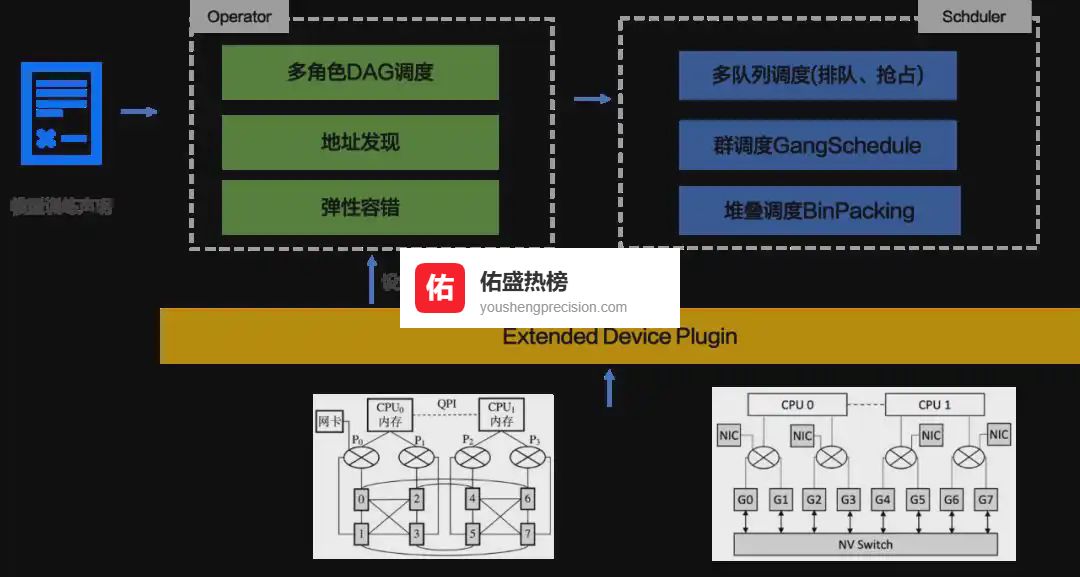
2.1 ▍ 高性能计算与存储的规模化调度硬件池化:CPU、GPU、网卡全进池,谁申请谁拿,用完即还。
编排引擎:Gang调度、多队列、网络亲和性,让“Worker、Server、Scheduler”一次到位,拒绝“有人先跑有人后跑”的尴尬。
超算集群:2000+ GPU、1 EFLOPS 算力、机内 600 GBps NVLink、亚毫秒级 vePFS 文件系统,把“读得快、写得快、算得快”做成标配。
2.2 ▍ 模型分布式训练加速计算侧:自研高性能算子库,norm、attention 等核心模块 比开源版快一个量级。
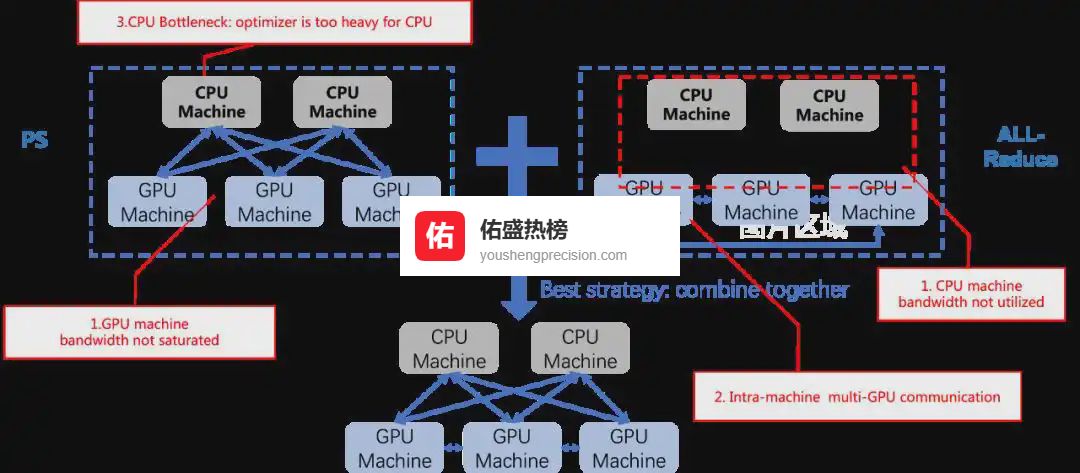
通信侧:BytePS 把 PS 与 All-Reduce 揉在一起,跨机 256 卡仍比原生框架快 245%。
显存侧:veGiantModel 支持混合并行,自动切分流水线,计算盖过通信,气泡归零。
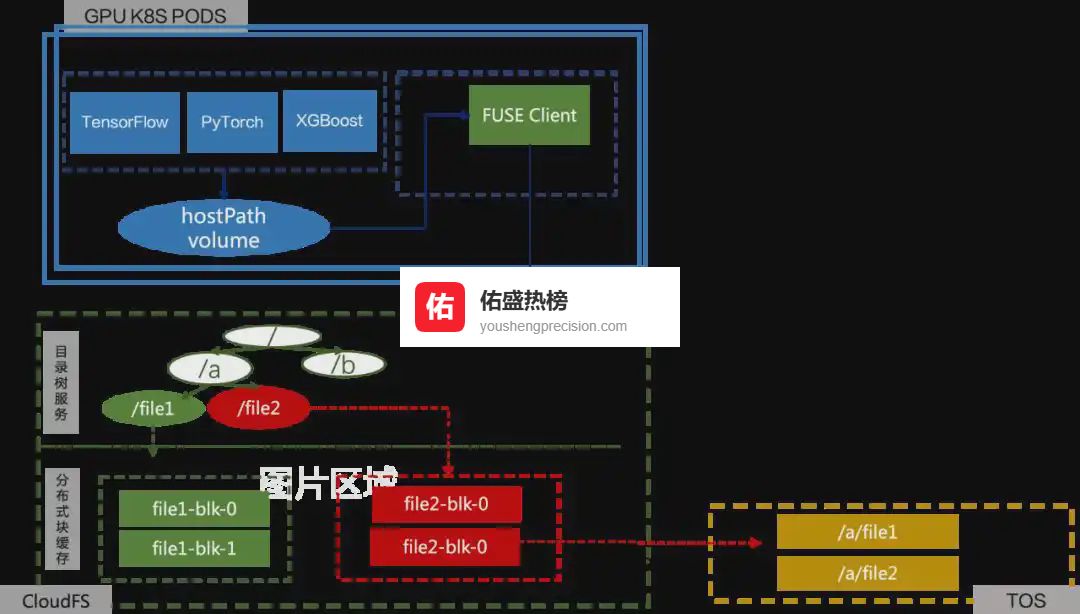
03云原生存储:让 PB 级数据“零损耗”穿梭
3.1 ▍ CloudFS 三件套FUSE Client:POSIX 接口,第二轮 epoch 直接读内存级缓存。
分布式 Blob 缓存:与 GPU 同机部署,百 Gbps 带宽把“首个 epoch”拖成“本地读写”。
目录树服务:百万 QPS 支撑小文件扁平化,上云下云一键搞定。
实验数据显示, 真实训练场景与纯内存 mock 差距不到 5%,虚拟化损耗被压到“几乎不可见”。
04BytePS:把通信成本砍到最低
4.1 ▍ 跨机通信梯度被智能拆分到所有 GPU/CPU, 等效于 PS+All-Reduce 的混合版,流量利用率直接拉满。
4.2 ▍ 机内通信NVLink/PCIe 被精心绕路, 避开热点竞争,网卡带宽被“喂饱”。
Communication Service 负责聚合,Summation Service 负责规约, CPU 只跑通信腿,GPU 负责跑道更新,内存瓶颈消失。
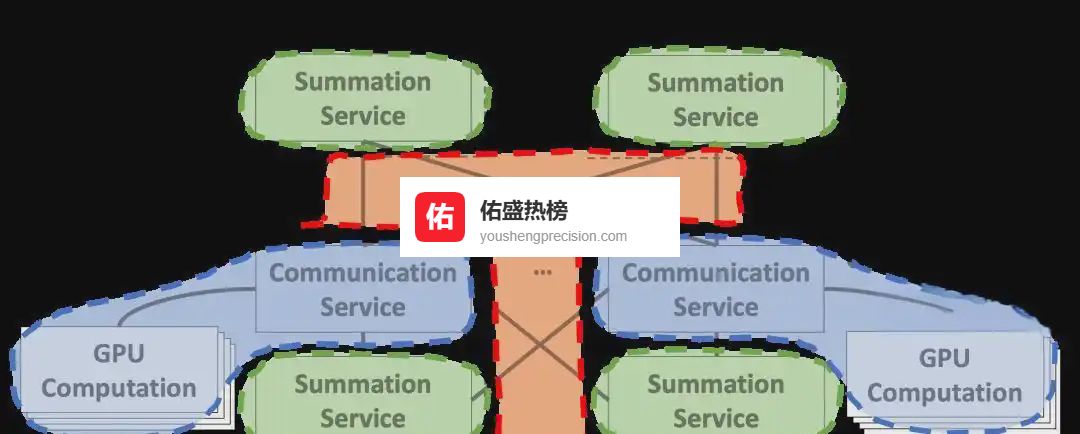
规模评估:8 卡到 256 卡,TensorFlow/PyTorch/MXNet 全线 比 All-Reduce 快 4%,比 PS 快 245%。开源地址已奉上,欢迎社区一起打怪升级。
05veGiantModel:混合并行的“均衡器”
Tensor 并行:NVLink/NVSwitch 把带宽拉到 TB 级,BytePS 做通信兜底。
数据并行:跨机照样跑飞起。
流水线并行:自动按参数量切分,计算盖过通信,气泡归零。
公开 Benchmark 显示, 对比 Megatron/DeepSpeed 提速 30+%,巨参模型也能“轻装上阵”。
06一站式开发:让算法同学“不折腾”就能跑飞起
 6.1 ▍ 多入口开发
6.1 ▍ 多入口开发 Web IDE、OpenAPI、交互式命令行、Python SDK 四条路都能上车,数据标注、离线推理、Kubeflow Pipeline 一键接入。
6.2 ▍ 开机不浪费开发机与 VM 语义对齐, 关机不丢状态、数据动态挂载、无需记 K8s 端口;VSCode、JupyterLab 一键拉起,开发效率肉眼可见地涨。
6.3 ▍ Job 化训练框架调度、硬件加速、日志、监控全栈打通, 每一次迭代都自动归档环境、代码、模型、日志;把日志喂给 OLAP 引擎,效果对比秒级完成,“谁跑得快”一目了然。
07真实案例:自动驾驶团队如何把迭代周期砍一半
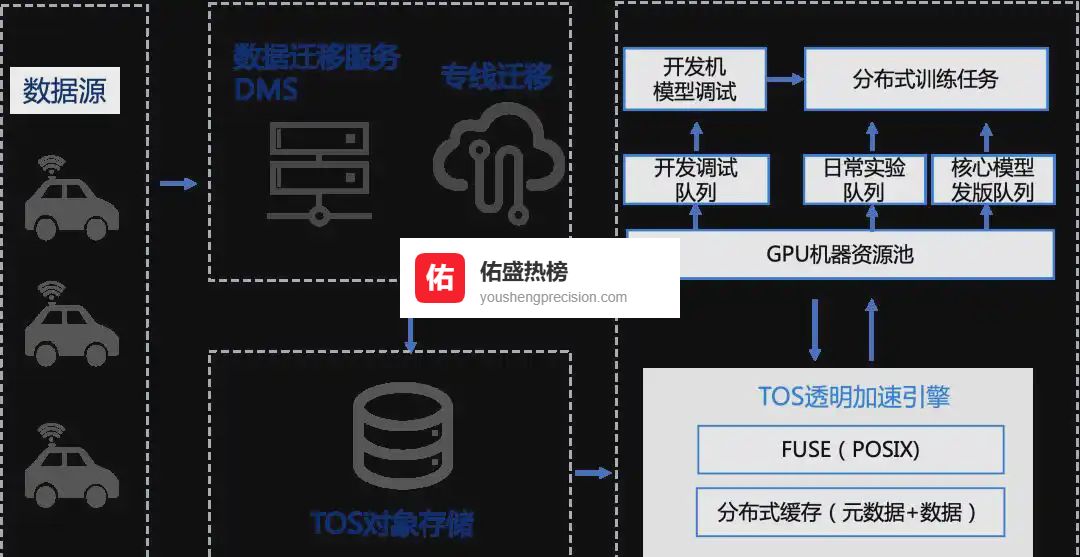
痛点:机器人工分配、人肉调度;最大只能上 16 卡;数据分散在多套存储,手工拷贝到吐。
做法:资源池化+排队调度;BytePS 把 Onboard 模型从 96 h 压到 30 h;数据先迁 TOS 再走 CloudFS 缓存,训练时读写都在“本地”。
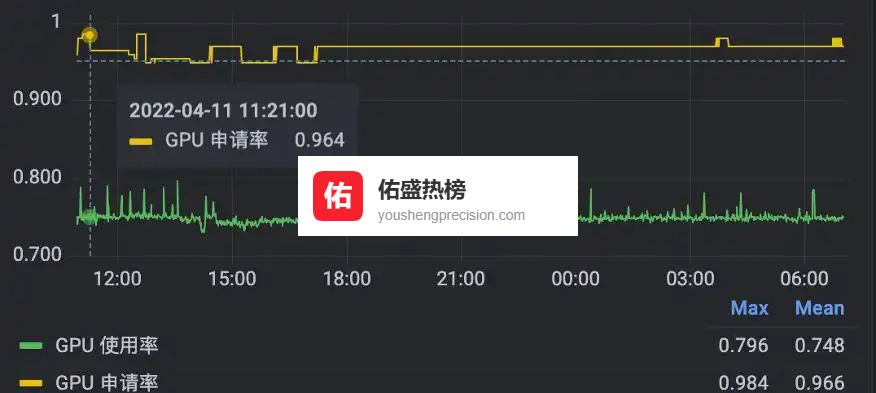
结果:资源利用率提升到 95% 以上,算法同学终于可以把“迭代”当日常操作。






