DSTC11赛道5:把“主观知识”装进任务型对话引擎
01赛事速览:任务型对话再升级
对话系统技术挑战赛(DSTC)走到2023年已是第十一届,赛道5首次把“主观知识”请进任务型对话——既要完成预订、问路等任务,又要把用户的“口碑”“情绪”一并考虑。主办方给出三大子任务:先判断是否需要外部知识,再从海量非结构化文档里“捞”出相关条目,最后生成兼顾任务目标与情感色彩的回复。14支队伍同台竞技,我们最终拿下客观指标第三,其中Turn Detection单项夺冠。
02赛题拆解:数据、定义与难点
2.1 ► 数据画像数据集由两部分拼成:
19696条“带主观知识”的对话,实体可单可多;
18383条“无主观知识”的MultiWOZ对话,纯任务导向。
知识分两种:
Review型长文本——多句组合,像“早餐选项超乎想象”;
FAQs问答对——简洁直接,如“退房时间几点?”。
实体分布在hotel与restaurant两大域,分别含33与110个业务条目。下图给出三条对话实例与对应知识条目示例:
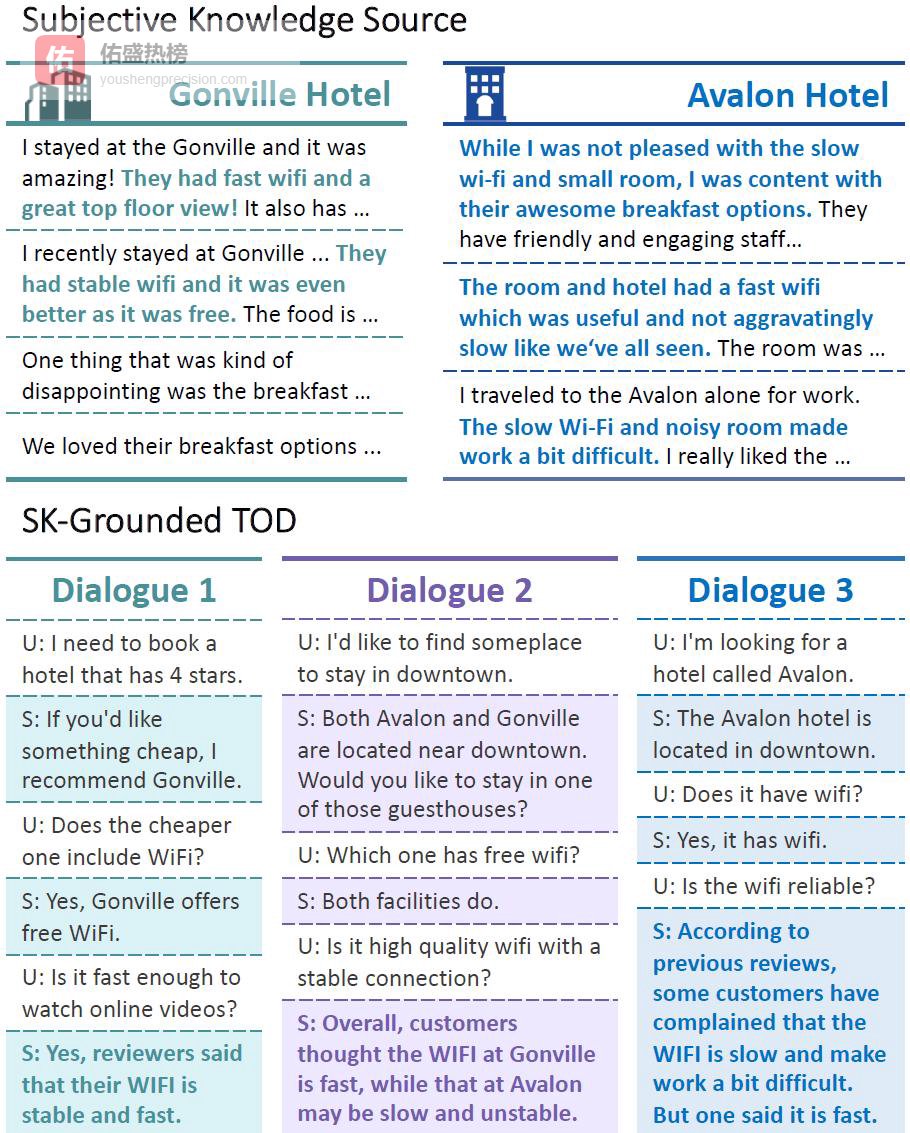 2.2 ► 问题定义
2.2 ► 问题定义 整个任务被拆成四步闭环:
Turn Detection:最后一轮查询是否需主观知识;
Entity Tracking:若需,锁定相关实体集合;
Entry Selection:从实体知识库里捞“干货”;
Response Generation:生成兼顾任务与情感的回复。
难点集中在三条:
知识条目数量不确定,有的对话对应零条,有的十余条;
训练集、验证集、测试集分布差异大,“未见场景”占比高;
不同知识条目情感倾向各异,回复时必须“算总账”。
2.3 ► 评价指标Turn Detection:Precision、Recall、F1;
Knowledge Selection:Precision、Recall、F1、Exact Match;
Response Generation:BLEU、METEOR、ROUGE-1/2/L。
最终客观分是五项倒数的和,越小越优。
2.4 ► 调研启示往届类似赛道不多,但前辈已踩过不少坑:
DSTC9-track1格式最简单,每轮只需一条最相关知识;
DSTC10-track2把书面语换成口语,泛化能力瞬间成焦点;
多人尝试数据增广:域分类+实体选择、语音相似扰动、掩码跨度语言建模、后处理Levenshtein距离修正……每招都在缩小“训练集偏见”。
03竞赛方案:从数据增强到模型融合
3.1 ► 数据增强双保险unseen数据集:把FAQ问答对随机塞进单实体对话,模拟话题跳转,再以80%概率拼成长对话;
noise数据集:用谷歌翻译回译再回译,生成语义级干扰,最后用Wordnet同义词替换,5倍扩充对话+知识库,再两两组合成25倍“大餐”。
3.2 ► Turn Detection:三路专家各显神通用DeBERTa-v3-base做自编码器,把对话上文+最后一轮查询扔进去,[CLS]向量喂线性层。为应对unseen场景,同步训练:
Seen expert:只在训练集微调;
Unseen expert:用unseen数据集微调RoBERTa;
De-noise expert:先用noise数据预训练,再用25倍含噪数据微调。
最终用差异感知融合——三种概率按逆相关度加权,并设阈值去噪。
3.3 ► Entity Track:n-gram匹配速胜给每个实体名称建词典,n-gram扫尾轮查询,F1=0.9676、Accuracy=0.9398,一步到位缩候选范围。
3.4 ► Entry Selection:精选“干货”知识条目把对话上文与知识候选一起喂编码器,拼接后算点积得相关度。训练时按1:1正负例采样;验证时只拿Entity Track圈定的实体知识做候选。同样三路expert+融合权重,保证既见过的也未见过的都能被“捞”到。
3.5 ► Response Generation:让知识“开口”说话试了GPT-2、BART、T5等多种架构,发现BART+KS-F1权重知识片段表现最优。为防Entity Track/Selection抖动,训练时:
把实体名拼进输入;
随机丢弃15%知识条目;
对比“全知识”vs“精选知识”两种输入版本,结果精选版更稳。此外还试验了LLAMA+instruction fine-tuning路线,可惜幻觉问题拖了后腿。
3.6 ► 融合魔法:差异感知权重公式以Entry Selection为例,对验证集每个实例 定义权重 (公式见上图)。超参数 随测试集unseen比例动态调整,保证 越大,Unseen expert权重越高。最终输出只保留权重≥阈值的知识条目,既保精度也保召回。算法流程见下图:

算法流程图(可横向拉大)
该套融合框架可无缝迁移到Turn Detection、Response Generation等阶段,做到“一处融合,多处受益”。
04结果复盘:单项冠军与整体第三的幕后功臣
4.1 ► Turn Detection 子任务验证集上 baseline 已很高,测试集新增 unseen 对话。我们用 F1 与 Recall 双指标学习融合参数,最终提交在 F1 与 Recall 两项分别拿下第一、第二,三项总和第一。
4.2 ► Knowledge Selection 子任务单模型略超 baseline,融合后性能飙升——EM 指标比 baseline 高出 14 个百分点。验证集按 F1+EM 双指标选最优模型提交,测试集表现依旧稳如老狗。为方便起见,把两套参数分别记作 KS-F1 与 KS-EM。
4.3 ► Response Generation 子任务本阶段不融合模型。实验显示 KS-F1 知识片段生成的回复在所有自动指标上全面领先 baseline;BART-large(KS-F1) 的 BLEU 更拿下 第二名;T5 在 ROUGE 与 METEOR 上也有亮点。整体看 KS-F1 知识质量最高,再次验证融合策略的正确性。
05未来展望:把“主观知识”装进更大的引擎
Knowledge Selection 可扩展到 Entity Track——当前只捞不跟踪,未来让实体也带权重;
区分 Review 与 FAQ 不同语义特性——FAQ 可能与用户查询高度相似,可单独建模;
生成端引入对话状态追踪与情感理解模型——增强抗干扰与情感一致性;
让大模型先“读懂”知识再交由生成模型续写——既保理解力也保任务完成度;
自动学习融合阈值——让算法自己找最优超参,进一步解放人力。






