从“大杂烩”到“纯正HBase”:集群部署与调优全纪录
01为什么HBase必须“出身名门”
HBase天生就是面向大规模并发、毫秒级响应的OLTP实时数据库,一旦落地再改架构,代价堪比“二次创业”。因此,“第一步怎么走”直接决定后续所有优化能否生效。
02第一阶段:硬件+软件“大杂烩”的坑
2.1 ▣ 集群画像规模:20台物理机
服务:HBase、Spark、Hive、Impala、Kafka、Zookeeper、Flume、HDFS、Yarn一站式部署
硬件:内存、CPU、磁盘参差不齐,典型“机房清库存”混搭
软件:直接套用CDH全家桶,“软件混合型”彻底跑通
这种配置在离线场景下毫无压力——批处理可以“用旧机、跑通宵”,只要结果正确就行。可一旦HBase被推向在线实时查询+高频写入的火线,问题瞬间爆发:
老机器拖后腿:哪怕只有一台RegionServer卡顿,线上延迟就会雪崩。
离线任务暴增IO:Spark、Hive一起抢盘,IO飙到10G/s,HBase响应直接拖尾。
磁盘与HDFS互踢:离线任务写满磁盘,HBase日志报“HDFS connection timeout”,线上服务跟着掉链子。
硬件混合型+软件混合型=化学爆炸式翻车,谁试谁知道。
03第二阶段:换新机≠换新体验
3.1 ▣ 升级动作全新采购30台高配服务器(后期扩容到40)
老机器直接退役,硬件层面“清零”
依旧把所有服务装在同一台机器上,“软件混合型”未拆分
规模扩大≠体验升级,线上延迟依旧偶发
问题根因依旧没动:
离线任务峰值IO > 4G/8G/5G任意一条红线,线上立刻抖动;
RegionServer CPU打满后整台机器假死,“朱丽叶死亡”现场频频出现;
想再扩机器?数据迁移停服务,线上交易根本等不起。
一句话:“早知今日,何必当初”——早点把HBase独立成集群,就不会被离线任务绑架。
04第三阶段:软硬件彻底“分家”
4.1 ▣ 设计思路15+5:15台RegionServer + 5台独立Zookeeper(虚拟节点分散部署)
零共享:Zookeeper不与HBase共宿,避免单点也避免“跨网请求不到”的尴尬
万兆网卡:千兆网络早已打满,万兆是底线;
磁盘够大:单台RS本地盘≥30T,配合高压缩比,给未来SubRegion留余量;
内存不盲堆:128G封顶,BucketCache吃堆外内存,GC友好;
CPU多核优先:Compaction、合并、分裂都是CPU密集型任务,核数多多益善。
4.2 ▣ Zookeeper数量红线别心疼机器,Zookeeper节点≥5且不在同一物理机。一旦物理机挂掉,相当于5个节点全灭,选举延迟会让整个集群心跳失控。
05Redis前置缓存:理论美好,现实骨感
为了撑住第二阶段的不稳定,临时拉了8台Redis做热点数据缓存,800G内存只装HBase热数据的20%。看似用户查询永远<10ms,可一旦Redis集群本身出现90%内存高压,照样OOM炸裂。事实证明:“前置缓存救急可以,但救不了架构短板”。
06Region规划:30G是道坎儿
官方推荐RegionSize落在10G–30G之间,超过30G就会出现:
大Region优点:迁移快、RPC少、Flush少
大Region缺点:Compaction一次吃不下,资源消耗爆表
小Region优点:负载均衡、HFile少、Compaction影响小
小Region缺点:频繁Split、Flush频繁、维护开销大
按30G上限算,18T硬盘是单RegionServer的“天花板”(SubRegion暂未商用)。当前配置把上限设为30G,单节点最多200个Region,刚好卡在理论红线。
07Memstore刷写:256M是平衡点
默认128M太敏感,设为256M可大幅减少频繁Flush带来的IO风暴;multiplier设为3,让Region级别再缓冲一下。关键要盯紧:
RS级别Flush:一旦触发就全栈阻塞,线上必卡;
ColumnFamily≤3:MemStore最小flush单位是Region,家族越多,每次flush越重。
08内存模型:BucketCache才是读多写少亲儿子
写多读少选LRUBlockCache,读多写少直接上BucketCache。核心公式记住一句:
Disk / JavaHeap = RegionSize / MemstoreSize ReplicationFactor HeapFractionForMemstore 2
按18T硬盘、30G Region、256M Memstore、3副本算,最理想JavaHeap≈60–40G。取40G堆内+BucketCache堆外,既减少GC又留足读缓存。堆外缓存比例按1:9分给B1(LRU元数据)+B2(用户数据),兼顾速度与安全。
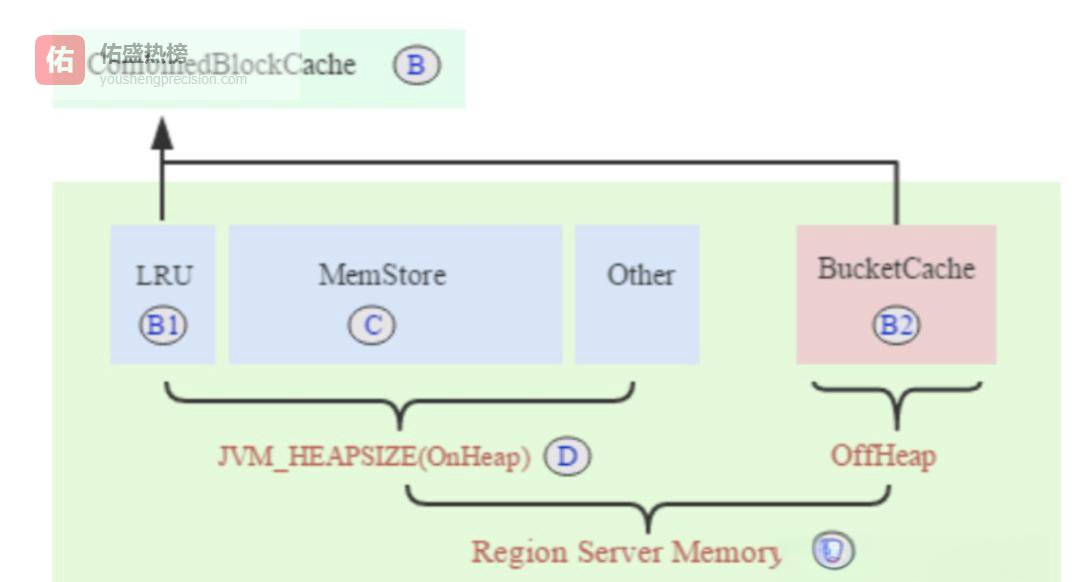
上图清晰展示BucketCache布局——LRU管元数据,堆外管热点数据,写缓存只管写入流。
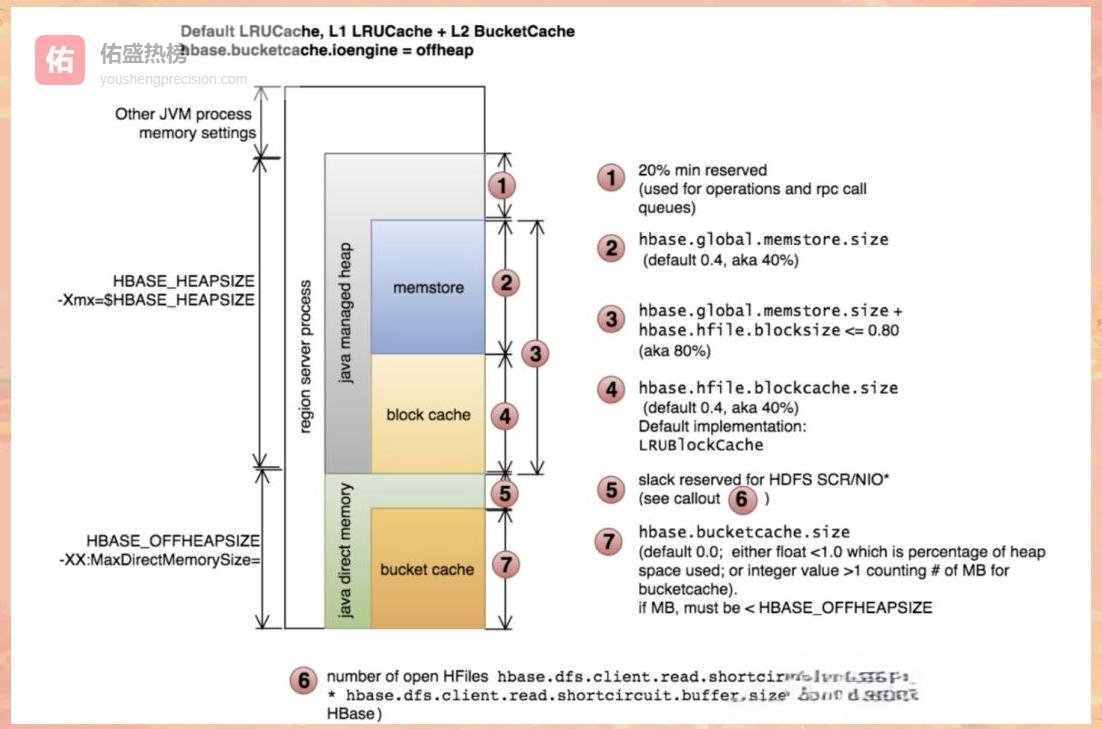
CDH官方图再次印证:堆外缓存是读多写少场景的“亲儿子”。
09读缓存与写缓存的安全线——80%红线别碰
任何组件一旦资源使用率>80%,就会进入“随时翻车”模式。经验之谈:
LRUBlockCache + MemStore < 80% JVM Heap(7.2+24)/40=0.78 → ≤0.8
hfile.block.cache.size + global.memstore.upperLimit ≤ 0.75 → ≤0.8
Redis前置层同样适用80%红线——90%内存直接OOM重启。
10服务端线程池:256不是万能钥匙
默认Master/RS线程池都设为256,看似够大,可一旦并发破万就出现“无法创建新线程”异常。调优思路:
动态扩容线程池(Guava或JDK自带)配合合理拒绝策略;
rpc.timeout降级到5s以内(默认60s太长),防止无限重试拖垮系统;
hstore.blockingStoreFiles调大到200–300(默认100),避免hfile堆积导致写入block。
11HDFS配套参数——别让文件系统拖后腿
datanode.handler.count=64 → 12288(大文件场景)
namenode.handler.count=256 → serviceHandlerCount=256(并发命名空间操作)
这些参数直接决定文件系统吞吐量与延迟,忽视即踩坑。
配置汇总表见文末“重要参数速查表”,一键抄作业即可。
12Spark对接HBase:连接池复用是灵魂
12.1 ▣ 流式查询——广播+延迟加载绕坑法(Scala示例)```scala
class HBaseSink(zhHost: String, confFile: String) extends Serializable {
lazy val connection = { // 只实例化一次,广播到所有节点
val hbaseConf = HBaseConfiguration.create()
hbaseConf.set(HConstants.ZOOKEEPER\_QUORUM, zhHost) // zk地址
hbaseConf.addResource(confFile) // 表结构文件
ConnectionFactory.createConnection(hbaseConf) // 建立连接 } } val broadcastSink = sc.broadcast(new HBaseSink("zkQuorum", "tableSchema")) // Driver端初始化广播变量 foreachPartition { partition => // 各分区取广播变量 value 的 connection 进行业务操作 } // 这样每个分区复用同一连接池,避免每条记录建一次连接 ``` ### 12.2 大批量写入——bulkload才是救世主 当实时写入+离线ETL双高峰叠加时,直接用`rdd.toHBase`会引发线上抖动甚至RegionServer宕机。解决思路只有一条: 离线任务用`hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles`或`hbase org.apache.hadoop.hbase.mapreduce.Export`做bulkload,一次性把数据灌进去;实时流用正常Client API写热区。唯一代价是离线IO高点,但换来线上稳定。## 13. JVM黑科技——G1 GC参数速查表(仅做参考) -XX:+UseG1GC -XX:InitiatingHeapOccupancyPercent=65 -XX:-ResizePLAB -XX:MaxGCPauseMillis=90 -XX:+UnlockDiagnosticVMOptions -XX:+G1SummarizeConcMark -XX:+ParallelRefProcEnabled -XX:G1HeapRegionSize=32m -XX:G1HeapWastePercent=20 -XX:ConcGCThreads=4 -XX:ParallelGCThreads=16 -XX:MaxTenuringThreshold=1 -XX:G1MixedGCCountTarget=64 -XX:+UnlockExperimentalVMOptions -XX:G1NewSizePercent=2 -XX:G1OldCSetRegionThresholdPercent=5 这些参数组合让HBase在读写混合场景下保持90%吞吐率同时把停顿时间压到90ms以内——亲测有效。## 14. 安全阀配置——手动Split与WAL编码 别忘了在regionserver标签里加上两行隐藏彩蛋: `<property> <name>hbase.regionserver.wal.codec</name> <value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value> </property> <property> <name>hbase.region.server.rpc.scheduler.factory.class</name> <value>org...(自定义调度器类)</value> </property> IndexedWALEditCodec让WAL编辑更紧凑;自定义调度器让高并发下请求响应更快——两者都是“看不见的减负神器”。## 15. 一张图看懂第三阶段全貌 ① 硬件彻底对齐——高配服务器+万兆网卡+大容量磁盘; ② 软件完全拆分——Zookeeper独立、HDFS独立、YARN独立; ③ HBase独享集群——RegionServer规模可弹性伸缩; ④ Redis做弹性缓冲——热点数据兜底但不背锅; ⑤ GC参数锁死80%红线——读写缓存分离策略严格执行; ⑥ Spark任务写冷区、离线任务做Bulkload——流量分流做到极致。 至此,HBase集群从“大杂烩”走向“纯正血统”,真正具备承载百万TPS、毫秒级响应的底气。




